Installation
eNMS is a Flask web application designed to run on a Unix server with Python 3.8+. The first section below describes how to get eNMS up and running quickly in demo mode to help in understanding what it is. The following sections give details for setting up a production environment.
First steps
The first step is to download the application. The user can download the latest release of eNMS directly to the browser by going to the Release section of eNMS github repository.
The other option is to clone the master branch of the git repository from github:
# download the code from github:
git clone https://github.com/eNMS-automation/eNMS.git
cd eNMS
Once the application is installed, the user must go to the eNMS folder and
install eNMS python dependencies:
# install the requirements:
pip install -r build/requirements/requirements.txt
Once the requirements have been installed, the user can run the application with the Flask built-in development server.
# set the FLASK_APP environment variable
export FLASK_APP=app.py
# start the application with Flask
flask run --host=0.0.0.0
For use in a production environment, it is advised to create a more robust environment for the application. The following sections describe the recommended requirements:
Database
By default, eNMS will use SQLite database. The user can configure a different database from SQLAlchemy's list of supported databases
For example, for a MySQL database, change the DATABASE_URL environment variable:
export DATABASE_URL="mysql://root:password@localhost/enms"
Flask Secret key
Provide a secret key used by Flask to sign sessions:
# set the SECRET_KEY environment variable
export SECRET_KEY=value-of-user-secret-key
Server Address
The address is needed when eNMS needs to provide a link back to the application, which is the case with webssh and mail notifications. When left empty, eNMS will try to guess the URL. This might not work consistently depending on the user's environment (nginx configuration, proxy, ...).
export SERVER_ADDR="http://192.168.56.102"
WSGI server
A WSGI HTTP server such as gunicorn is required to run eNMS in production, instead of the Flask development server.
A recommended configuration file for gunicorn is in the main folder: gunicorn.py;
it is recommended to run the application with the following command:
# start the application with gunicorn
gunicorn --config gunicorn.py app:app
Dramatiq
Dramatiq, a distributed task queue, can be used for executing automations:
- In setup/settings.json set
"use_task_queue": true - Set the
REDIS_ADDRenvironment variable and rundramatiq eNMSfrom the project root.- The number of worker processes and threads can be configured (among other things). Run
dramatiq --helpto see the full list of Dramatiq's command-line options.
- The number of worker processes and threads can be configured (among other things). Run
WebSSH
The SSH_URL can be set to specify which web address to use when connecting to network devices through web-based SSH.
Hashicorp Vault
All credentials should be stored in a Hashicorp Vault: the settings
variable use_vault : true under the vault section of the
setup/settings.json file tells eNMS that a vault has been set up.
Follow the manufacturer instructions and options for how to set up a
Hashicorp Vault
Tell eNMS how to connect to the Vault with environment variables:
VAULT_ADDRESSVAULT_TOKEN
eNMS can also unseal the Vault automatically at start time. This
mechanism is disabled by default. To activate it, one must set
unseal_vault : true in setup/settings.json and set the UNSEAL_VAULT_KEY
environment variables :
export UNSEAL_VAULT_KEY1=key1
export UNSEAL_VAULT_KEY2=key2
etc
Plugin Installation
Any initial eNMS Plugins - like the sample eNMS CLI Plugin - can also be installed here. See Plugins for more details.
Environment variables
Environment variables for all sensitive data (passwords, tokens, keys) are exported from Unix and include:
- SECRET_KEY=secret_key
- MAIL_PASSWORD=mail_password
- TACACS_PASSWORD=tacacs_password
- SLACK_TOKEN=slack_token
Example Systemd Unit and Socket files and Nginx config with proxy-pass
enms.gunicorn.socket
[Unit]
Description=gunicorn socket for enms
[Socket]
ListenStream=/run/gunicorn/enms.gunicorn.socket
[Install]
WantedBy=sockets.target
enms.gunicorn.service
[Unit]
Description=Gunicorn instance to serve enms
Requires=enms.gunicorn.socket
Requires=vault.service
After=network.target
After=mysqld.service
After=enms.gunicorn_scheduler.service
After=vault.service
[Service]
PermissionsStartOnly=true
PIDFile=/run/gunicorn/enms.gunicorn.pid
User=centos
Group=centos
WorkingDirectory=/home/centos/enms
ExecStartPre=/bin/mkdir -p /run/gunicorn/
ExecStartPre=/bin/chown -R centos:centos /run/gunicorn/
# Add the virtualenv to the PATH
Environment="PATH=/opt/python3-virtualenv/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:."
ExecStartPre=/bin/echo Setting application PATH to $PATH
Environment="http_proxy=http://proxy.company.com:80/"
Environment="https_proxy=http://proxy.company.com:80/"
Environment="NO_PROXY=localhost,127.0.0.1,169.254.169.254,.company.com,W.X.Y.Z/8,A.B.C.D/16"
Environment="HOSTNAME=HOSTNAME_CHANGEME"
Environment="SECRET_KEY=SECRET_KEY_CHANGEME"
Environment="VAULT_ADDR=http://127.0.0.1:8200"
Environment="VAULT_LOG_LEVEL=info"
Environment="VAULT_TOKEN=VAULT_TOKEN_CHANGEME"
Environment="UNSEAL_VAULT_KEY1=VAULT_KEY1_CHANGEME"
Environment="UNSEAL_VAULT_KEY2=VAULT_KEY2_CHANGEME"
Environment="UNSEAL_VAULT_KEY3=VAULT_KEY3_CHANGEME"
Environment="SCHEDULER_ADDR=http://127.0.0.1:8000"
# To indicate which server a service was run from in Automation/Run table
Environment="SERVER_NAME=CHANGE_ME"
Environment="SERVER_ADDR=CHANGE_ME"
# Use Fernet Key additional encryption for stored passwords - not compatible with loading
# eNMS example migration files (comment out for examples)
Environment="FERNET_KEY=SOME_FERNET_VALID_KEY"
Environment="ENMS_ADDR=https://127.0.0.1"
Environment="ENMS_PASSWORD=ENMS_PASSWORD_CHANGEME"
Environment="REDIS_ADDR=127.0.0.1"
Environment="LDAP_ADDR=ldap://MYCOMPANY_CHANGEME"
Environment="LDAP_USERDN=MYCOMPANY_CHANGEME"
Environment="LDAP_BASEDN=DC=my,DC=ad,DC=company,DC=com"
Environment="TACACS_PASSWORD=CHANGEME"
Environment="MAIL_PASSWORD=CHANGEME"
Environment="SLACK_TOKEN=CHANGEME"
Environment="FLASK_APP=app.py"
Environment="FLASK_DEBUG=1"
# PATH to TextFSM repo for Netmiko: https://pynet.twb-tech.com/blog/automation/netmiko-textfsm.html
Environment="NET_TEXTFSM=/home/centos/ntc_textfsm/"
Environment="GUNICORN_ACCESS_LOG=logs/access.log"
Environment="GUNICORN_LOG_LEVEL=debug"
Environment="DATABASE_URL=mariadb+mysqldb://root:PASSWORD@localhost/enms?charset=utf8mb4"
ExecStart=/opt/python3-virtualenv/bin/bin/gunicorn --pid /run/gunicorn/enms.gunicorn.pid --worker-tmp-dir /tmpfs-gunicorn --bind unix:/run/gunicorn/enms.gunicorn.socket --chdir /home/centos/enms --config /home/centos/enms/gunicorn.py app:app
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s TERM $MAINPID
TimeoutStopSec=60
LimitNOFILE=100000
[Install]
WantedBy=multi-user.target
enms.dramatiq.service
[Unit]
Description=Dramatiq instance to run workers
After=network.target
After=mysqld.service
After=vault.service
[Service]
PermissionsStartOnly=true
User=centos
Group=centos
WorkingDirectory=/home/centos/eNMS
# Add the virtualenv to the PATH
Environment="PATH=/opt/python3-virtualenv/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:."
ExecStartPre=/bin/echo Setting application PATH to $PATH
Environment="http_proxy=http://proxy.company.com:80/"
Environment="https_proxy=http://proxy.company.com:80/"
Environment="NO_PROXY=localhost,127.0.0.1,169.254.169.254,.company.com,W.X.Y.Z/8,A.B.C.D/16"
Environment="HOSTNAME=HOSTNAME_CHANGEME"
Environment="SECRET_KEY=SECRET_KEY_CHANGEME"
Environment="VAULT_ADDR=http://127.0.0.1:8200"
Environment="VAULT_LOG_LEVEL=info"
Environment="VAULT_TOKEN=VAULT_TOKEN_CHANGEME"
Environment="UNSEAL_VAULT_KEY1=VAULT_KEY1_CHANGEME"
Environment="UNSEAL_VAULT_KEY2=VAULT_KEY2_CHANGEME"
Environment="UNSEAL_VAULT_KEY3=VAULT_KEY3_CHANGEME"
Environment="SCHEDULER_ADDR=http://127.0.0.1:8000"
# To indicate which server a service was run from in Automation/Run table
Environment="SERVER_NAME=CHANGE_ME"
Environment="SERVER_ADDR=CHANGE_ME"
# Use Fernet Key additional encryption for stored passwords - not compatible with loading
Environment="FERNET_KEY=SOME_FERNET_VALID_KEY"
Environment="ENMS_ADDR=https://127.0.0.1"
Environment="ENMS_PASSWORD=ENMS_PASSWORD_CHANGEME"
Environment="REDIS_ADDR=127.0.0.1"
Environment="LDAP_ADDR=ldap://MYCOMPANY_CHANGEME"
Environment="LDAP_USERDN=MYCOMPANY_CHANGEME"
Environment="LDAP_BASEDN=DC=my,DC=ad,DC=company,DC=com"
Environment="TACACS_PASSWORD=CHANGEME"
Environment="MAIL_PASSWORD=CHANGEME"
Environment="SLACK_TOKEN=CHANGEME"
# PATH to TextFSM repo for Netmiko: https://pynet.twb-tech.com/blog/automation/netmiko-textfsm.html
Environment="NET_TEXTFSM=/home/centos/ntc_textfsm/"
Environment="DATABASE_URL=mariadb+mysqldb://root:PASSWORD@localhost/enms?charset=utf8mb4"
ExecStart=/opt/python3-virtualenv/bin/dramatiq eNMS
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutStopSec=60
LimitNOFILE=100000
[Install]
WantedBy=multi-user.target
nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 120;
types_hash_max_size 2048;
fastcgi_buffers 8 16k;
fastcgi_buffer_size 32k;
fastcgi_connect_timeout 900;
fastcgi_send_timeout 900;
fastcgi_read_timeout 900;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
server {
# port to listen on. Can also be set to an IP:PORT
listen 443 http2 ssl default_server;
listen [::]:443 http2 ssl default_server;
server_name enms-hub;
server_name_in_redirect on;
server_tokens off;
ssl_certificate /etc/ssl/certs/nginx.pem;
ssl_certificate_key /etc/ssl/private/nginx.key;
ssl_dhparam /etc/ssl/certs/dhparam.pem;
client_max_body_size 0;
client_body_buffer_size 10K;
client_header_buffer_size 1k;
ssl_protocols TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
ssl_ciphers "EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH";
ssl_ecdh_curve secp384r1;
ssl_buffer_size 16k;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 4h; # 4 hours to reuse sessions
ssl_session_tickets off;
ssl_stapling off;
ssl_stapling_verify off;
# Disable preloading HSTS for now. One can use the commented out header line that includes
# the "preload" directive if one understands the implications.
#add_header Strict-Transport-Security "max-age=63072000; includeSubdomains; preload";
add_header Strict-Transport-Security "max-age=63072000; includeSubdomains";
add_header X-Frame-Options DENY;
add_header X-Content-Type-Options nosniff;
root /usr/share/nginx/html;
# Load configuration files for the default server block.
#include /etc/nginx/default.d/*.conf;
# Enable compression for larger files/results
gzip on;
gzip_types text/plain application/xml application/json text/json text/xml;
gzip_proxied no-cache no-store private expired auth;
gzip_min_length 100000;
gunzip on;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_pass http://unix:/run/gunicorn/enms.gunicorn.socket;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_connect_timeout 300s;
# Should match the gunicorn timeout:
proxy_read_timeout 7200s;
}
# Use regex for terminal urls:
location ~ ^/terminal(.*)$ {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header Host $host;
rewrite ^/terminal(\d*)/(.*)$ /$2 break;
proxy_pass http://127.0.0.1:$1;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
# Setup enms Documentation link
location /docs/ {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
# Added to expose access to the separate/remote scheduler.
server {
listen 8000;
listen [::]:8000;
server_name enms-scheduler;
root /usr/share/nginx/html;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_pass http://unix:/run/gunicorn/enms.gunicorn_scheduler.socket;
proxy_connect_timeout 300s;
# Should match the gunicorn timeout:
proxy_read_timeout 7200s;
}
}
}
Note
Importing the files/migrations/examples migration files requires that
the FERNET_KEY environment variable be unset (not defined) and that the
hash_user_passwords parameter in setup/settings.json be set to True
because of how the sample passwords are stored in the examples. The
files/migrations/default migration files that most production
deployments start with do not contain passwords, so loading them does not
impose the same requirements.
Note
Deploying eNMS into an environment that uses proxy url redirection
requires that the http_proxy=, https_proxy=, and NO_PROXY=
environment variables be set if that is needed to reach certain endpoints,
such as the network_data repository for device configuration data.
Settings Files
The application's setup files are located in setup/, and the following
section describes their contents:
automation.json
The setup/automation.json file allows for the customization of some
automation library options, such as Napalm Getters, the default contents
of the parameterized run form for workflows, the default arguments used to
open a Scrapli connection, and the models that one can access or create
from the workflow builder global variables.
Key parameters to be aware of:
always_commit: (default:false) Always commit results and logs immediately after they are created when a service is running. This can help prevent various database issues that arise during a run.connection_args: These parameters are sent to the Netmiko or Scrapli connection handler before establishing the connection. To see which parameters are supported, you should check the Netmiko or Scrapli documentation.disconnect_thread_timeout: (default:10(seconds)) This parameter sets the timeout value used when attempting to close all open connections at the end of a workflow. Multiple threads are spawned to close all connections as quickly as possible, and this timeout is passed to each thread.notification: This parameter determines which notification mechanisms are available in Step 4 of the Service Panel, as well as in the service type drop-down lists in the Workflow Builder and Service Table. By default, all notification mechanisms (email, Slack, and Mattermost) are enabled.truncate_logs: (default:falsewith amaximum_sizeof200000000) This parameter determines whether to trim the logs of a service before saving them to the database if they exceed a certain size limit (maximum_size).
database.json
The setup/database.json file contains database and schema configuration
parameters. Make sure to include a new database engine section here if
switching to another SQLAlchemy supported database variant.
Key parameters to be aware of:
pool_size(default:1000) Number of connections kept persistently in SQL Alchemy pool.max_overflow(default:10) Maximum overflow size of the connection pool.tiny_string(default:64) Length of a tiny string in the database.small_string(default:255) Length of a small string in the database.large_string(default:429496729) Length of a large string in the database.pickletype(default:16777215) Length of a list or dictionary in the database.
logging.json
Logging settings exist in the file setup/logging.json. This
file is directly passed into the Python Logging library, so it uses the
Python3 logger file configuration syntax for the user's version of Python3.
Using this file, the administrator can configure additional loggers and
logger destinations as needed for workflows.
Key advanced parameters to be aware of:
use_multiprocessing_handlers(default:true) Tell the application to use a specific handler calledMultiProcessingLoggingHandlerfor logging. This handler helps prevent issues related to concurrent access to logs from multiple threads during a service run.
By default, the two loggers are configured:
- The default logger has handlers for sending logs to the stdout
console as well as a rotating log file
logs/enms.log. - A security logger captures logs for: User A ran Service/Workflow
B on Devices [C,D,E...] to log file
logs/security.log.
And these can be reconfigured here to forward through syslog to remote collection if desired. This can also be used as a means to send workflow data to remote time series databases for dashboarding and longer term storage of automation results data.
Additionally, the external loggers section allows for changing the log
levels for the various libraries used by eNMS.
With multiple gunicorn workers, please consider:
- Using
Python WatchedFileHandlerinstead of theRotatingFileHandler. - Configuring the LINUX
logrotateutility to perform the desired log rotation.
Example logging.json that allows for logging to a time series database in the workflow's post-processing section or via python snippet service:
{
"version": 1,
"disable_existing_loggers": false,
"formatters": {
"standard": {
"format": "%(asctime)s %(levelname)-8s %(message)s"
},
"rsyslogdFormatter": {
"format": "%(filename)s: %(funcName)s: %(message)s"
},
"timeseriesSyslogFormatter": {
"format": "logtype=\"workflow\" %(message)s"
},
},
"handlers": {
"console": {
"level": "DEBUG",
"formatter": "standard",
"class": "logging.StreamHandler",
"stream": "ext://sys.stdout"
},
"rotation": {
"level": "DEBUG",
"formatter": "standard",
"filename": "logs/enms.log",
"class": "logging.handlers.WatchedFileHandler"
},
"security": {
"level": "DEBUG",
"formatter": "rsyslogdFormatter",
"class": "logging.handlers.SysLogHandler",
"address": "/dev/log",
"facility": "local3"
},
"timeseries": {
"level": "INFO",
"formatter": "timeseriesSyslogFormatter",
"class": "logging.handlers.SysLogHandler",
"address": ["X.X.X.X", PortYYYY]
},
},
"loggers": {
"": {
"handlers": ["console", "rotation"],
"level": "DEBUG"
},
"security": {
"handlers": ["security"],
"level": "DEBUG",
"change_log": true,
"service_log": true
},
"timeseries": {
"handlers": ["timeseries"],
"level": "INFO"
},
},
"external_loggers": {
"engineio": "error",
"requests": "info",
"socketio": "error",
"urllib3": "info",
"werkzeug": "error"
}
}
properties.json
The setup/properties.json file includes:
- Allowing for additional custom properties to be defined in eNMS for devices and links. In this way, eNMS device inventory can be extended to include additional columns/fields.
- Allowing for additional custom parameters to be added to services and workflows.
- Controlling which parameters and widgets can be seen from the Dashboard.
- Controlling which column/field properties are visible in the tables for device and link inventory, configuration, pools, as well as the service, results, and task browsers.
- Pull-down choices for
Category,Model,Operating System, andVendor.
For examples, please see Custom Properties for more information
rbac.json
The setup/rbac.json file allows configuration of which user roles have
access to each of the controls in the UI, as well as which user roles have
access to each of the REST API endpoints.
settings.json
The setup/settings.json file includes the following public variables which
are also modifiable from the administration panel. Changing settings from the
administration panel will cause settings.json to be rewritten if Write changes
back to settings.json file is selected.
app section
config_mode(default:"debug") Must be set to"debug"or"production".documentation_url(default:"https://enms.readthedocs.io/en/latest/") Can be changed if one wants to host one's own version of the documentation locally. Points to the online documentation by default.git_repository(default:"") Git is used as a version control system for device configurations: this variable is the address of the remote git repository where eNMS will push all device configurations.plugin_path: (default:"eNMS/plugins") location of eNMS plugin extensions and customizations.session_timeout_minutes: (default:90).startup_migration(default:"examples") Name of the migration to load when eNMS starts for the first time.- By default, when eNMS loads for the first time, it will create a network topology and a number of services and workflows as examples of what the user can do.
- One can set the migration to
"default"instead, in which case eNMS will only load what is required for the application to function properly.
nameChoose the application name that will appear on the login page, in the upper left corner after logging in, and in the browser tab.themeSelect the default theme that will be automatically applied when creating new user accounts.
authentication section
Lists the methods available for users to login (in order of which they
are shown in the login screen pulldown list). Default authentication is
specified here. Because authentication can be custom for many
environments, eNMS/custom.py allows the user to customize how the
authentication needs to occur. It can be modified to fit a company's
ldap active directory system, etc.
For LDAP authentication, by default, the application looks for the LDAP_ADDR
environment variable and initializes a single LDAP server.
If that variable is not set, it looks for the servers key under
authentication > methods > ldap. The servers key is a dictionary that maps
LDAP server IPs/URLs to their keyword parameters, based on the syntax
supported by the ldap3 Python library.
Example syntax for LDAP:
"ldap": {
"display_name": "LDAP",
"enabled": true,
"servers": {
"192.168.56.104": {
"port": 636,
"use_ssl": true
}
}
},
DUO two-factor authentication can be configured through the settings in authentication > duo (client ID, host, and redirect URI) and the DUO_SECRET environment variable.
Example syntax for DUO authentication:
"duo": {
"config": {
"client_id": "DIRUY3ZRHXYYHVOZDMIW",
"host": "api-58bbe24c.duosecurity.com",
"redirect_uri": "https://enms:5000/duo-callback"
},
"enabled": false
},
automation section
max_processlimit on multiprocessing (default: 15).use_task_queueuse dramatiq for service execution (default: false).
cache section
config: settings given toflask_caching.Cache(default:{"CACHE_TYPE": "SimpleCache"})timeout: time limit (in seconds) set for thecacheddecorator, after which a stored page is removed from the cache (default:500)
cluster section
Section used for detecting other running instances of eNMS.
- active (default: false).
- id (default: true).
- scan_subnet (default: "192.168.105.0/24").
- scan_protocol (default: "http").
- scan_timeout (default: 0.05).
docs section
This section is used to configure which pages in the documentation to open for some of the embedded information (help) links. This should not need to be changed.
dashboard section
Define how the charts are displayed in the dashboard section in the user interface. The apache echarts javascript package is used to render these charts and the value in this section are set as the charts' option. Documentation on echart options here.
label(default{"normal": {"formatter":"{b} ({c})"}})series(default[{"type": "pie"}])tooltip(default{"formatter": "{b} : {c} ({d}%)"})
files section
Control how the app tracks files on the filesystem.
monitor_filesystemmanages the monitoring of file changes on the systemignored_typesfile extensions to exclude from tracking (default:[".swp"," .tgz"])upload_timeout(default:600000)log_eventslog changes (modify/update/delete) of tracked files to both the console and changelog (default:true)trashpath to the "trash" folder where deleted files are moved
mail section
reply_to(default:"no_replies@company.com").server(default:"smtp.googlemail.com").port(default:587).use_tls(default:true).username(default:"eNMS-user").sender(default:"eNMS@company.com").
mattermost section
url(default:"https://mattermost.company.com/hooks/i1phfh6fxjfwpy586bwqq5sk8w").channel(default:"").verify_certificate(default:true).
notification section
This section is covered in depth in the administration panel portion of the docs. Below are the default values.
activedefault (false)deactivate_on_restartdefault (true)propertiesautoclosedefault ("30s")contentdefault ("<center>The Server is <b>restarting at 3:30 UTC.</b><br>Contact <b>adress@domain.com</b> for more information.</center>")contentSizedefault ("600 auto")headerdefault (false)opacitydefault (0.85)positiondefault ("center-bottom 0 -10 up")themedefault ("danger filleddark")
paths section
files(default:"") Path to eNMS managed files needed by services and workflows. For example, files to upload to devices.custom_code(default:"") Path to custom libraries that can be utilized within services and workflows.custom_services(default:"") Path to a folder that containsCustom Services. These services are added to the list of existing services in the Automation Panel when building services and workflows.playbooks(default:"") Path to where Ansible playbooks are stored so that they are selectable in the Ansible Playbook service.
pool section
fast_compute(default:true) use raw SQL queries to empty and insert the object IDs in the pool in order to speed up the pool update mechanism
redis section
This section allows configuration of the Redis queue.
charset(default:"utf-8").db(default:0).decode_responses(default:true).port(default:6379).socket_timeout(default:0.1).
requests section
Allows for tuning of the Python Requests library internal structures for connection pooling. Tuning these might be necessary depending on the load on eNMS.
-
Pool
-
pool_maxsize(default:10). pool_connections(default:100).-
pool_block(default:false). -
Retries
-
total(default:2). read(default:2).connect(default:2).backoff_factor(default:0.5).
security section
forbidden_python_libraries(default:["eNMS","os","subprocess","sys"]) There are a number of places in the UI where the user is allowed to run custom python scripts. The user can configure which python libraries cannot be imported for security reasons.
slack section
channel(default:"").
ssh section
command(default:python3 -m flask run -h 0.0.0.0): command used to start the SSH server.-
credentials: which credential types to enable for the WebSSH connection feature.custom(default:true).device(default:true).user(default:true).
-
port_redirection(default:false). bypass_key_prompt(default:true).port(default:-1).start_port(default:9000).end_port(default:9100).
tables section
Configure the refresh rates of a table in the UI in milliseconds. By default, the "Results" page (run table) will be refreshed every 5 seconds, and the "Services" and "Tasks" pages every 3 seconds.
run(default:5000).service(default:3000).task(default:3000).
vault section
For eNMS to use a Vault to store all sensitive data (user and network
credentials), one must set the active variable to true, provide an
address and export:
active(default:false).unseal(default:false) Automatically unseal the Vault.
The keys must be exported as environment variables:
VAULT_ADDRESSVAULT_TOKENUNSEAL_VAULT_KEY1UNSEAL_VAULT_KEY2UNSEAL_VAULT_KEY3UNSEAL_VAULT_KEY4UNSEAL_VAULT_KEY5
themes.json
The setup/themes.json file exposes some configurable parameters for the
default and dark appearance themes of the application.
visualization.json
The setup/visualization.json file controls the visualization map portion
of the application. The user can specify whether the visualization defaults
to '2D' mode (recommended for large inventories) or '3D' mode. Also, the
default latitude and longitude of the map can be set here.
Key parameters to note:
default("2D"or"3D").longitude(default:-96.0).latitude(default:33.0).zoom_level(default:5).tile_layer(default:"osm").marker(default:"Circle").
Key parameters for the network builder:
display_nodes_as_images(true): displaying nodes as images can be slower if there are too many nodes.max_allowed_nodes(500): threshold above which eNMS will not try to display a network (too much data).
Scheduler
The scheduler, used for running tasks at a later time, is a web application that is distinct from eNMS. It can be installed on the same server as eNMS, or a remote server.
Before running the scheduler, one must configure the following environment variables so it knows where eNMS is located and what credentials to authenticate with:
ENMS_ADDR: URL of the remote server (example:"http://192.168.56.102").ENMS_USER: eNMS login.ENMS_PASSWORD: eNMS password.
The scheduler is an asynchronous application that must be deployed with gunicorn :
cd scheduler
gunicorn scheduler:scheduler --host 0.0.0.0
Example Systemd Unit and Socket files
Above nginx.conf sample has a section for eNMS Scheduler
enms.gunicorn_scheduler.socket
[Unit]
Description=Gunicorn socket for eNMS scheduler
[Socket]
ListenStream=/run/gunicorn/enms.gunicorn_scheduler.socket
[Install]
WantedBy=sockets.target
enms.gunicorn_scheduler.service
[Unit]
Description=Start eNMS Scheduler service using Gunicorn
Requires=enms.gunicorn_scheduler.socket
After=network.target
After=mysqld.service
[Service]
PermissionsStartOnly=true
PIDFile=/run/gunicorn/enms.gunicorn_scheduler.pid
User=centos
Group=centos
WorkingDirectory=/home/centos/enms/eNMS
ExecStartPre=/bin/mkdir -p /run/gunicorn/
ExecStartPre=/bin/chown -R centos:centos /run/gunicorn/
Environment="ENMS_ADDR=https://127.0.0.1"
Environment="ENMS_PASSWORD=CHANGE_ME"
Environment="ENMS_USER=admin"
Environment="VERIFY_CERTIFICATE=0"
Environment="REDIS_ADDR=127.0.0.1"
Environment="SCHEDULER_ADDR=http://127.0.0.1:8000"
Environment="GUNICORN_ACCESS_LOG=/home/centos/enms/logs/access_scheduler.log"
Environment="GUNICORN_LOG_LEVEL=info"
Environment="DATABASE_URL=mysql://root:PASSWORD@localhost/enms?charset=utf8"
ExecStart=/opt/python3-virtualenv/bin/gunicorn --pid /run/gunicorn/enms.gunicorn_scheduler.pid --worker-tmp-dir /tmpfs-gunicorn --bind unix:/run/gunicorn/enms.gunicorn_scheduler.socket --chdir /home/centos/enms/scheduler --config /home/centos/enms/scheduler/gunicorn.py scheduler:scheduler
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s TERM $MAINPID
TimeoutStopSec=60
LimitNOFILE=100000
[Install]
WantedBy=multi-user.target
scheduler.json
The setup/scheduler.json file controls the behavior of the eNMS Scheduler
application.
Network Data Merge Driver
eNMS features easy access to up-to-date device configurations and
network data. A service can be configured to periodically collect the latest
configurations direct from devices in a network, after which a backend
process can leverage Git to synchronize data between all instances of the
application. These files can be found in the network_data/ repository of
each VM, organized by device name.
Services can also be configured to update only their instance's local repository. This intended functionality has been known to cause merge conflicts during automatic synchronizations with the shared remote repository.
To prevent this, a git merge driver can be used to programmatically resolve merge conflicts. Such drivers typically utilize a combination of git attributes, configuration instructions, and custom scripts to function. Below are all the components of a proposed driver for the Network Data repositories:
network_data/.gitattributes
...
* merge=newest
...
This line in the attributes file instructs git to associate the merge method named "newest" for every file (through the wildcard character) in the repository.
network_data/.git/config
...
[merge "newest"]
name = Merge by newest commit
driver = git-merge-newest %O %A %B %L %P master FETCH_HEAD
[branch "master"]
mergeoptions = --no-edit
...
When added to the existing .git/config, these lines define a new merge
strategy and provide the necessary command line arguments, as well as several
placeholder values handled by git. More
detailed descriptions of these values (along with additional resources on custom
merge drivers in general) are available in Git's documentation.
network_data/git-merge-newest
#!/bin/sh
if git merge-file -p -q "$2" "$1" "$3" > /dev/null;
then git merge-file "$2" "$1" "$3";
else
MINE=$(git log --format="%ct" --no-merges "$6" -1);
THEIRS=$(git log --format="%ct" --no-merges "$7" -1);
if [ $MINE -gt $THEIRS ]; then
git merge-file -q --ours "$2" "$1" "$3" >/dev/null
else
git merge-file -q --theirs "$2" "$1" "$3">/dev/null
fi
fi
The shell script defines the logic and commands to run when the merge driver
is called. In this case it compares the timestamps from git log commands on
the local master branch and the contents of FETCH_HEAD, accepting the most
recent result.
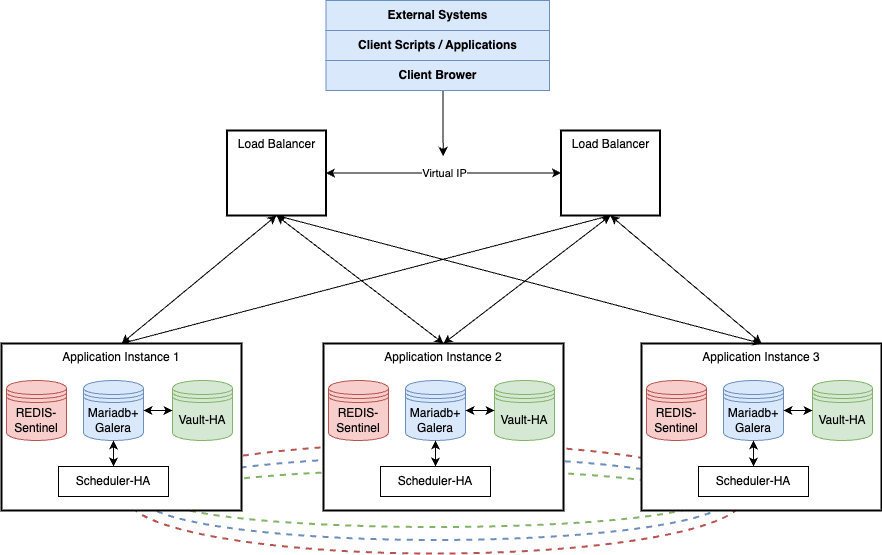
Galera Cluster Deployment on Rocky Linux
A clustered deployment (pictured below) makes use of galera, vault HA with a mysql storage backend, and redis-sentinel to keep the application instances in sync. It's recommended to deploy application instances in odd numbers (3,5,7 etc.) to avoid a split-brain situation with galera. A Load Balancer like HAProxy can utilize either an existing REST API endpoint or add a custom one for the application to identify instances that are ready to be used. Additionally, connecting to REDIS through the Load Balancer can simplify the REDIS client configuration.
Step 1: System Update
sudo dnf update -y
Step 2: Build MariaDB Connector
sudo dnf groupinstall "Development Tools" -y
sudo dnf install cmake openssl-devel -y
tar -xzvf mariadb-connector-c-3.3.8-src.tar.gz
cd mariadb-connector-c-3.3.8-src
mkdir build
cd build
cmake ..
make
sudo make install
# This gives the path /usr/local/lib to the right connector
find /usr/local -name "libmariadb.so*"
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
export LIBRARY_PATH=/usr/local/lib:$LIBRARY_PATH
export C_INCLUDE_PATH=/usr/local/include/mariadb:$C_INCLUDE_PATH
export CPLUS_INCLUDE_PATH=/usr/local/include/mariadb:$CPLUS_INCLUDE_PATH
echo 'export LD_LIBRARY_PATH=/usr/local/lib/mariadb:$LD_LIBRARY_PATH' >> ~/.bashrc
echo 'export LIBRARY_PATH=/usr/local/lib/mariadb:$LIBRARY_PATH' >> ~/.bashrc
echo 'export C_INCLUDE_PATH=/usr/local/include/mariadb:$C_INCLUDE_PATH' >> ~/.bashrc
echo 'export CPLUS_INCLUDE_PATH=/usr/local/include/mariadb:$CPLUS_INCLUDE_PATH' >> ~/.bashrc
source ~/.bashrc
echo "/usr/local/lib/mariadb" | sudo tee /etc/ld.so.conf.d/mariadb.conf
sudo ldconfig
python3 -m pip install --force-reinstall mariadb
Step 3: Install MariaDB Server
sudo dnf install mariadb-server -y
sudo systemctl start mariadb
sudo systemctl enable mariadb
sudo mysql_secure_installation
Step 4: Install Galera Cluster
sudo dnf install -y mariadb-server-galera
sudo firewall-cmd --permanent --add-service=galera
sudo firewall-cmd --reload
Step 5: Configure Galera
Edit the configuration file:
sudo nano /etc/my.cnf.d/mariadb-server.cnf
and add the following configuration:
wsrep_on=ON
wsrep_cluster_address="gcomm://192.168.56.103,192.168.56.104"
binlog_format=row
wsrep_node_address="192.168.56.104"
wsrep_cluster_name="my_galera_cluster"
wsrep_sst_auth="sstuser:password"
wsrep_sst_method=rsync
bind-address=0.0.0.0
Step 6: Create 'sstuser' in database
sudo mysql -u root -p
CREATE USER 'sstuser'@'%' IDENTIFIED BY 'password';
GRANT RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT ON *.* TO 'sstuser'@'%';
FLUSH PRIVILEGES;
Step 7: Start Galera Cluster
On VM1:
sudo galera_new_cluster
sudo systemctl start mariadb
sudo mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size';"
Expected output:
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 1 |
+--------------------+-------+
On VM2:
sudo systemctl restart mariadb
sudo mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size';"
Expected output:
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 2 |
+--------------------+-------+
Cluster Management Script
This script (build/script/cluster.sh)provides several commands to manage the Galera cluster.
cluster -s | --start
Starts a new Galera cluster:
- Stops the MariaDB service.
- Initializes a new Galera cluster.
- Starts and enables the MariaDB service.
- Checks the status of the MariaDB service and the cluster.
To be used on the first node of the cluster, not for joining an existing cluster.
cluster -c | --check
Checks the status of the MariaDB service and various Galera cluster parameters:
- MariaDB service status.
- Cluster size.
- Node state and connection status.
- Provider and version details.
- IP addresses of cluster nodes.
cluster -d | --delete
Uninstalls MariaDB and deletes data and configuration files.
cluster -i | --install
Installs MariaDB and Galera:
- Installs MariaDB server and Galera.
- Starts and enables MariaDB service.
- Runs the secure installation script.
cluster -r | --restart
Restarts the MariaDB service.